一个 TCP 接收缓冲区问题的解析
本文是作为一个 TCP 发送缓冲区问题的解析的姊妹篇存在的,在 TCP 中,接收缓冲区比发送缓冲区更为重要和复杂,原因就是,接收缓冲区和 TCP 通告的窗口也息息相关。
问题模型

Clinet 与 Server 之间建立一条 TCP 连接,Server 通过 SO_RCVBUF 选项设置连接的接收缓冲区为 2048 字节。Clinet 每隔 100 ms 通过 send() 一个载荷长度很小(2 字节)的 TCP 报文,但 Server 端不调用 recv(),这意味着 Server 收到的 TCP 报文都会存放在接收缓冲区,而当接收缓冲区满时,便应该向 Client 通告零窗口(Zero-Window)
但实际情况是:
- Server 最后并没有发送零窗口,它最小的通告窗口也有 874
- Server 没有回应 Clinet 的重传报文,导致 Clinet 重传次数过多后断开
下面是抓包的结果
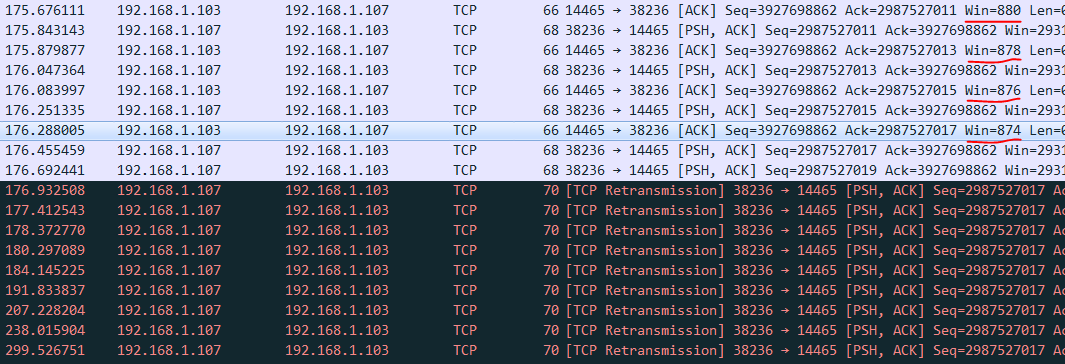
所以,为什么会这样?
双倍接收缓冲区
与发送缓冲区的实现一致,当用户通过 SO_RCVBUF 选项设置缓冲区大小时,内核会将这个设置值加倍,比如我们在这里设置 2048 字节,内核实际的缓冲区大小时 4096 字节
case SO_RCVBUF:
......
/*
* We double it on the way in to account for
* "struct sk_buff" etc. overhead. Applications
* assume that the SO_RCVBUF setting they make will
* allow that much actual data to be received on that
* socket.
*
* Applications are unaware that "struct sk_buff" and
* other overheads allocate from the receive buffer
* during socket buffer allocation.
*
* And after considering the possible alternatives,
* returning the value we actually used in getsockopt
* is the most desirable behavior.
*/
sk->sk_rcvbuf = max_t(u32, val * 2, SOCK_MIN_RCVBUF);
break;
这样做的原因注释中有写,是因为sk_buff有额外开销(下面会细说),而接收缓冲区的大小是指用于缓存所有收到的sk_buff 的内存,它会包含额外开销,所以这里内核将这个值扩大一倍。
sk上还有两个字段十分重要,sk->sk_rmem_alloc表示当前已经使用的接收缓冲区内存,sk->forward_alloc表示预先向内核分配到的内存。这两个字段有什么关系呢?
打个比方,sk->forward_alloc就好比充值的点卡,sk->sk_rmem_alloc则用来记录实际花销。当需要花费内存时,内核总是先看sk->forward_alloc有没有,如果没有,则向系统申请内存,放到sk->forward_alloc里,之后再花费时,发现sk->forward_alloc还有,就直接扣这里面的就行了。而当sk->forward_alloc花光时,则又会重新充值.
内核一次充值sk->forward_alloc的大小为 1 个 PAGESIZE,一般为 4K。
sk_buff 究竟占据多大的空间
sk_buff的结构在 skbuff详解或者skb_data中已经有详细描述。我画了一张图
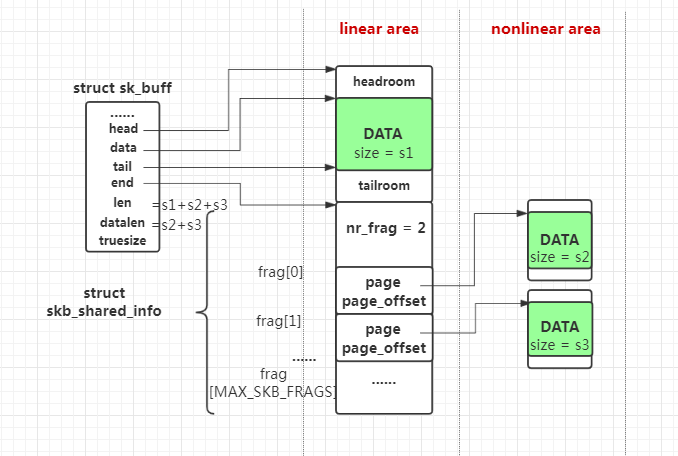
sk_buff分为sk_buff结构本身、线性区域(linear area)和非线性区域(nonlinear area)。sk_buff结构本身的大小在不同版本内核略有不同,但经过 2 的整次冥向上取整之后都为 256 Bytes,线性区域又分为数据存储区(skb->head到skb->end之间的部分)和skb_shared_info区域, 整个区域大小根据创建sk_buff时请求的大小确定,比如我们的例子中的包含 2B 用户数据的 TCP 报文,其线性区域大小经过向上取整后为 512B (预留头 64 Bytes + MAC头14 Bytes + IP头20 Bytes + TCP头 32 Bytes + 用户数据 2 Bytes + skb_shared_info结构 320 Bytes = 452 Bytes)。非线性区域不一定存在,如果存在则是挂在skb_shared_info的frag槽中,skb_shared_info一共有MAX_SKB_FRAGS+1个槽,在PAGESIZE=4K的情况下,这个值为 18。
三部分占用的内存总和才是一个sk_buff真正占用的内存(也就是应该受到sk->rcvbuf限制的),它的值记录在skb->truesize,而skb->datalen表示非线性区域用户数据的长度,skb->len表示线性+非线性区域用户数据的长度。
所以在我们例子中,Server端收到的sk_buff的长度信息应该是
skb->truesize = 768
skb->datalen = 0
skb->len = 2
Merge sk_buff
上面的例子中,一个sk_buff存储 2 字节用户数据,却要占用 768 字节的内存。如果收到的每个报文都要这么保存,那么接收缓冲区会被立即耗尽。因此内核在接收队列有sk_buff还没有被用户读取时,如果再收到sk_buff,会先尝试将后一个sk_buff的数据放到接收队列的最后一个sk_buff中。
static int __must_check tcp_queue_rcv(struct sock *sk, struct sk_buff *skb, int hdrlen,
bool *fragstolen)
{
int eaten;
struct sk_buff *tail = skb_peek_tail(&sk->sk_receive_queue);
__skb_pull(skb, hdrlen);
eaten = (tail && tcp_try_coalesce(sk, tail, skb, fragstolen)) ? 1 : 0;
tcp_rcv_nxt_update(tcp_sk(sk), TCP_SKB_CB(skb)->end_seq);
if (!eaten) {
__skb_queue_tail(&sk->sk_receive_queue, skb);
skb_set_owner_r(skb, sk);
}
return eaten;
}
sk_buff也不是随意就可以 Merge 的,它需要目标sk_buff有足够的空间容纳它的数据。
我们知道sk_buff分为线性区域和非线性区域,内核在合并sk_buff时,如果此时还没有使用非线性区域(skb_shared_info->nr_frag = 0),并且线性区域的剩余空间能装下新到的sk_buff,那么就将用户数据拷贝到目标sk_buff,否则再去尝试占用一个非线性区域中空闲的槽
那么,在我们的环境中,队列尾的sk_buff线性区域还能添加多少用户数据呢?
答案是 512 - 452 = 60 字节。也就是说,第 2 到第 31 个sk_buff可以直接合并到第 1 个sk_buff的线性区域,这些报文并不会增加缓冲区的内存占用sk->rmem_alloc,因为它们已经计算在sk->truesize了.
此时
tail_skb->truesize = 768
tail_skb->datalen = 0
tail_skb->len = 62
sk->sk_rmem_alloc = 768
sk->sk_forward_alloc = 3328
第 32 个报文时到达时,由于线性区域已经满了,它只能去占据非线性区域的槽
那么,它将占用多少接收缓冲区的内存呢?
第 32 个报文的信息和此时 sk 的状态为
skb->truesize = 768
skb->datalen = 0
skb->len = 34 // 这里还有 32 字节的 TCP 首部
它将占用除了skb->truesize - sizeof(struct sk_buff) = 512的接收缓冲区空间,换句话说,存入非线性区域能节省一个sk_buff结构的空间。
所以,第 32 个报文到达后,
tail_skb->truesize = 1280
tail_skb->datalen = 2
tail_skb->len = 64
sk->sk_rmem_alloc = 1280
sk->sk_forward_alloc = 2816
以此类推,第 33 个报文到达时,会变成
tail_skb->truesize = 1792
tail_skb->datalen = 4
tail_skb->len = 66
sk->sk_rmem_alloc = 1792
sk->sk_forward_alloc = 2304
到第 37 个报文,
tail_skb->truesize = 3840
tail_skb->datalen = 12
tail_skb->len = 74
sk->sk_rmem_alloc = 3840
sk->sk_forward_alloc = 256
也就是说,sk->sk_rmem_alloc增加多少,sk->sk_forward_alloc就相应减少多少。
sk_forward_alloc 充值
当sk->sk_forward_alloc = 256已经不够一个skb->truesize = 768时,内核会调用下面的 tcp_try_rmem_schedule()
此时,sk->sk_rmem_alloc并没有超过sk->sk_rcvbuf,所以下面的第一个条件并不满足,此时便会调用sk_rmem_schedule()对sk->sk_forward_alloc进行充值
static int tcp_try_rmem_schedule(struct sock *sk, struct sk_buff *skb, unsigned int size)
{
if (atomic_read(&sk->sk_rmem_alloc) > sk->sk_rcvbuf ||
!sk_rmem_schedule(sk, skb, size)) {
if (tcp_prune_queue(sk) < 0)
return -1;
// code omitted
}
}
TCP prune(修剪)
之后的报文依然会会消耗sk->sk_forward_alloc,同时增加sk->sk_rmem_alloc相同的数值,甚至超过sk->sk_rcvbuf
而当sk->sk_forward_alloc再次耗尽,内核再次调用tcp_try_rmem_schedule()时,此时sk->sk_rmem_alloc已经超过了sk->sk_rcvbuf,因此内核会调用tcp_prune_queue对接收队列上的报文进行修剪。
这次的手段是将非线性区域的用户数据移动到线性区域。
可是线性区域不是满了吗?
内核采用的做法是将sk_buff的 headroom 腾出来(不要预留区域、MAC头、IP头、TCP头了),然后进行非线性区域到线性区域的移动。
比如在我们的例子中,接收队列的tail_skb的基本信息为
prune 之前,
tail_skb->truesize = 7936
tail_skb->datalen = 28
tail_skb->len = 90
tail_skb->data - tail_skb->head = 130
tail_skb->end - tail_skb->tail = 0
sk->sk_rmem_alloc = 7936
sk->sk_forward_alloc = 256
而在 prune 之后,
tail_skb->truesize = 768
tail_skb->datalen = 0
tail_skb->len = 90
tail_skb->data - tail_skb->head = 0
tail_skb->end - tail_skb->tail = 130
sk->sk_rmem_alloc = 768
sk->sk_forward_alloc = 3328
经过这一番腾挪,tail_skb没有了非线性区域,并且线性区域的尾部就又可以装 130 字节(65 个报文)。
而当又收到 65 个报文之后,tail_skb的线性区域又耗尽了,此后的报文又会开始往非线性区域累加。
直到sk->sk_rmem_alloc又接近sk->sk_rcvbuf
tail_skb->truesize = 7936
tail_skb->datalen = 28
tail_skb->len = 220
tail_skb->data - tail_skb->head = 0
tail_skb->end - tail_skb->tail = 0
sk->sk_rmem_alloc = 7936
sk->sk_forward_alloc = 256
这个时候内核会对tail_skb的线性空间进行扩容,扩容之后线性空间能容纳 684 字节的用户数据了(其中 220 字节已经被使用)
tail_skb->truesize = 1280
tail_skb->datalen = 0
tail_skb->len = 220
tail_skb->data - tail_skb->head = 0
tail_skb->end - tail_skb->tail = 484
sk->sk_rmem_alloc = 1280
sk->sk_forward_alloc = 2816
再这之后,又是先填充线性区域,再填充非线性区域,再填充和扩容…..
诡异的 TCP 的通告窗口
RFC 中规定 TCP 使用滑动窗口来接收报文,并且在首部中向对端通告可用的窗口大小
那么应该通告多大的窗口呢? 不同内核有不同的实现
就初始通告窗口来说。Linux 的初始通告窗口设置为接收接收缓冲区的一半,且向下调整为 MSS 的整数倍。在我们的实验环境中,MSS 为 1448 Bytes,而接收缓冲区一半大小为 4096/2 = 2048 Bytes,因此,Server 的初始通告窗口也就是 1448 Bytes。

同样,后续的 TCP 报文也需要向对方通告接收窗口大小,但 RFC 1122 要求 TCP 还需要采取一定措施避免出现糊涂窗口综合征(SWS)
A TCP MUST include a SWS avoidance algorithm in the receiver.
RFC 1122 将接收缓冲区分为了以下三部分:其中,RCV.USER为收到并且已经ACK,但还没有被用户读取走的部分。RCV.WND为通告的窗口大小,静默状态下(没有报文传输时),RCV.USER=0,RCV.WND=RCV.BUFF.
|<---------- RCV.BUFF ---------------->|
1 2 3
|<-RCV.USER->|<--- RCV.WND ---->|
----|------------|------------------|------|----
RCV.NXT
1 - RCV.USER = data received but not yet consumed;
2 - RCV.WND = space advertised to sender;
3 - Reduction = space available but not yet advertised.
The solution to receiver SWS is to avoid advancing the right window edge RCV.NXT+RCV.WND in small increments, even if data is received from the network in small segments.
对于接收端来说,它应该避免小步幅(small increments)地推进窗口的右边沿(RCV.NXT+RCV.WND),怎么做呢? RFC 的推荐算法是
The suggested SWS avoidance algorithm for the receiver is to keep RCV.NXT+RCV.WND fixed until the reduction satisfies: RCV.BUFF - RCV.USER - RCV.WND >= min( Fr * RCV.BUFF, Eff.snd.MSS )
Fr的推荐值为 1/2。翻译过来就是,当满足可用的缓冲区超过了 min(缓冲区的一半,有效MSS) 时,将RCV.WND设置为RCV.BUFF-RCV.USER,否则接收端就不推进右边沿。
回到我们环境中, 我们可以发现 Linux 并没有采用 RFC 的建议,除了初始接收窗口的选择之外,由于我们 Server 没有调用recv(),按照 RFC 的算法,当收到报文时,RCV.NXT 推进,窗口又边沿不变,必然使得 RCV.WND 变小。
但从抓包结果来看,Server 通告的窗口大小变化趋势是先在一定时间内保持不变,后来才逐渐减小,再不变一段时间,再减小….。
窗口选择
为什么会这样呢?
在内核__tcp_select_window()的注释中是这么写的
/*
* Unfortunately, the recommended algorithm breaks header prediction,
* since header prediction assumes th->window stays fixed.
*
* Strictly speaking, keeping th->window fixed violates the receiver
* side SWS prevention criteria. The problem is that under this rule
* a stream of single byte packets will cause the right side of the
* window to always advance by a single byte.
*/
意思是 Linux 内核自己的首部预测算法与 RFC 中建议的接收端糊涂窗口综合征避免算法本身就是有冲突的。而 Linux 选择了使用首部预测算法。
什么是首部预测?
在 Linux 内核中,有两条路径处理收到的报文:快速路径(fast path)和慢速路径(slow path)。正如其名,快速路径处理预期中的报文,慢速路径则可以处理预期外的报文,比如乱序报文、紧急数据等。
Linux 总是倾向于走快速路径,这需要报文满足预测条件,内核将预测报文存放在 tp->pred_flags, 该标志预测收到报文的 TCP 首部中的 [11:14] 偏移的内容。
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Source Port | Destination Port |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Sequence Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Acknowledgment Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Data | |U|A|P|R|S|F| |
| Offset| Reserved |R|C|S|S|Y|I| Window | <---- tp->pred_flags
| | |G|K|H|T|N|N| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Checksum | Urgent Pointer |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Options | Padding |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| data |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
可以看到,通告窗口就在[11:14]范围内,所以走快速的条件之一是收到报文的通告窗口不能变化。
还有一个走快速路径的条件是,收到报文的大小不能超过sk->sk_forward_alloc的剩余值,若果超过,则说明sk 上预先分配的内存空间不够了,需要走慢速路径重新分配内存.
void tcp_rcv_established(struct sock *sk, struct sk_buff *skb,
const struct tcphdr *th, unsigned int len)
{
// code omitted...
if ((int)skb->truesize > sk->sk_forward_alloc)
goto step5;
}
TCP 报文中通告窗口的值由 tcp_select_window()决定
static u16 tcp_select_window(struct sock *sk)
{
struct tcp_sock *tp = tcp_sk(sk);
u32 old_win = tp->rcv_wnd;
u32 cur_win = tcp_receive_window(tp);
u32 new_win = __tcp_select_window(sk); // 计算新的窗口
/* Never shrink the offered window */
if (new_win < cur_win) {
if (new_win == 0)
NET_INC_STATS(sock_net(sk),
LINUX_MIB_TCPWANTZEROWINDOWADV);
new_win = ALIGN(cur_win, 1 << tp->rx_opt.rcv_wscale);
}
// code omitted
}
上面的逻辑关键在于使用 __tcp_select_window(sk) 计算新的窗口大小。注意那个条件判断,它的依据是
RFC 规定了 offered 过窗口不能 shrink,这并不是说通告窗口的值只能变大不能变小,而是说滑动窗口右边沿不能左移。比方说在某个时刻 Server 的通告窗口为 1448,当它收到 X 字节用户数据后,不允许将窗口减小为比 1448 - X 还小的值。
来看看新的窗口是怎么做的
u32 __tcp_select_window(struct sock *sk)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct tcp_sock *tp = tcp_sk(sk);
/* MSS for the peer's data. Previous versions used mss_clamp
* here. I don't know if the value based on our guesses
* of peer's MSS is better for the performance. It's more correct
* but may be worse for the performance because of rcv_mss
* fluctuations. --SAW 1998/11/1
*/
int mss = icsk->icsk_ack.rcv_mss;
int free_space = tcp_space(sk);
int allowed_space = tcp_full_space(sk);
int full_space = min_t(int, tp->window_clamp, allowed_space);
这里的 mss 取自icsk->icsk_ack.rcv_mss,这个值实际上是估计值,用来估算对方的MSS,依据就是如果对方发送的最大的 TCP 报文中的载荷长度(在tcp_measure_rcv_mss()中更新),在我们的环境中,
由于 Clinet 一直都是发送的 2 字节的小包,所以这个值在我们的环境中一直都是初始值 TCP_MSS_DEFAULT(536)
当sysctl_tcp_adv_win_scale = 1时(默认值),allowed_space表示整个接收缓冲区的空间的一半,free_space则表示接收缓冲区中空闲空间的一半,
if (free_space < (allowed_space >> 4) || free_space < mss)
return 0;
当空闲空间不到整个空间的 1/16 或者小于估算MSS时,本端计算出来的新窗口为 0,但这只是计算出的值,TCP头中通告窗口字段由于 RFC 规定窗口不能收缩,因此并不一定真正会通告零窗口(Zero-Window)
接下来计算新窗口为估算MSS的整数倍或者保持不变
/* Get the largest window that is a nice multiple of mss.
* Window clamp already applied above.
* If our current window offering is within 1 mss of the
* free space we just keep it. This prevents the divide
* and multiply from happening most of the time.
* We also don't do any window rounding when the free space
* is too small.
*/
if (window <= free_space - mss || window > free_space)
window = (free_space / mss) * mss;
else if (mss == full_space &&
free_space > window + (full_space >> 1))
window = free_space;
问题发生的过程
前面铺垫了这么多,现在我们来将它们串起来,看看本文最开始的问题是如何产生的。
Step 0 准备工作
通过 SO_RCVBUF 选项,设置接收缓冲区大小为 2048 字节。内核将这个值加倍,于是sk->sk_rcvbuf = 4096,初始通告窗口为 1448 字节。同时接收缓冲区内存消耗为sk->sk_rmem_alloc = 0
Step 1 第一个用户报文到达
第一个 skb (len = 2, truesieze = 768)到达时,此时接收队列上没有其他 skb,于是直接挂在了队列上,整个 skb 的报文内存占用计入sk->rmem_alloc = 768.
Step 2 后续若干个用户报文填入线性区域
后续若干个 skb 到达时,填入第一个 skb 的线性区域,sk->sk_rmem_alloc始终保持为 768 字节,sk->sk_forward_alloc始终保持为 3328 字节 。
对窗口来说,sk->sk_rmem_alloc 没有变化,每次收到 2 字节数据,会让计算出的cur_win = old_win - 2
old_win = 1448
cur_win = 1446
new_win = 1448
这个阶段,为了让收包一直走快速路径,Server 一直都向对端通告 1448 字节的窗口。
Step 3 后续若干个用户报文填入非线性区域
在开始往非线性区域填充之后,每个 skb 都将让sk->sk_rmem_alloc增加 512 字节,sk->sk_forward_alloc 减小 512 字节。这样 6 个报文之后, sk->sk_forward_alloc就消耗地差不多了,容不下下一个报文了。怎么办?再预分配啊,于是sk->sk_forward_alloc 变成了 4096 字节。之后又可以愉快地再增加sk->sk_rmem_alloc了。
也许你会疑问,这个过程中不会 check sk->sk_rcvbuf = 4096限制吗?实际上,内核只会在慢速路径为sk->sk_forward_alloc分配内存时才会去 check 是否超过了缓冲区大小,走快速路径时压根不管这个限制。
在我们的例子中,内核第一次走慢速路径为sk->sk_forward_alloc预分配内存时,sk->sk_rmem_alloc只是接近但并没有到 4096 字节,所以sk->sk_forward_alloc能顺利地加上 4K 字节。这让sk->sk_rmem_alloc之后可以超过sk->sk_rcvbuf,内核TCP的缓冲区限制是一条软限制,它允许超过,但超过后就不能再为sk->sk_forward_alloc预分配内存了。
再看窗口,第 1 个填入非线性区域的报文到达后,free_space 减小了,导致new_win的值也减小
old_win = 1448
cur_win = 1446
new_win = 1072 // 536 的 两倍
虽然new_win只有 1072 字节,但由于窗口不能收缩的原则,Server 端也只能老老实实地通告 cur_win = 1446 ,比之前的少了两个字节。
当第二个报文到达之后,同样的道理,通告窗口又减小 2 个字节,变成了 1444 字节。
接下来 1442、1440、1438、1436 …..
Step 4 TCP prune 发生
在 prune 之前,Server 通告窗口大小为 1420 字节 (并不是按照内存占用算出这么多,而是 TCP 只能减少到这么多)
如前面所说,第一次 prune 之后,tail_skb 会腾出线性空间,接下来的报文又可以往线性空间里塞了,这段时间内,通告窗口将保持不变,依旧为 1420 字节。
Step 5 后续若干个用户报文填入线性区域
同 Step 2 类似,为了让收包一直走快速路径,这个阶段 Server 一直都向对端通告 1420 字节的窗口。
Step 6 后续若干个用户报文填入非线性区域
同 Step 3 类似,这个阶段受制于窗口不能收缩的原则,Server 通告的窗口缓慢地从 1420 字节开始减小。1418、1416、1414……直到下一次 prune 发生。
接下来,重复 Step 5 至 Step 6。Server 通告的发送窗口也就依次保持不变、减小、不变、减小…..
那么这样下去,是否窗口就会减到 0 呢?
Step 7 最后阶段的 TCP prune
最后阶段的 TCP prune 前夕,窗口大小为 874 字节。
tail_skb 和 sk 的状态是这样的:
tail_skb->truesize = 7936
tail_skb->datalen = 22
tail_skb->len = 1750
tail_skb->data - tail_skb->head = 0
tail_skb->end - tail_skb->tail = 0
sk->sk_rmem_alloc = 7936
sk->sk_forward_alloc = 256
此时收到一个新的报文,由于 sk->sk_forward_alloc 已经不够了,所以会走慢速路径去 prune 接收队列上的 tail_skb
prune 结果是这样的:
tail_skb->truesize = 4352
tail_skb->datalen = 0
tail_skb->len = 1750
tail_skb->data - tail_skb->head = 0
tail_skb->end - tail_skb->tail = 202
sk->sk_rmem_alloc = 4352
sk->sk_forward_alloc = 3840
tail_skb->truesize和sk->sk_rmem_alloc缩小到了 4352 字节,线性区域尾部腾出了 202 字节的空间,非线性区没有了。
但是它占用的内存超过了sk->sk_rcvbuf, 因此 tcp_prune_queue() 和 tcp_try_rmem_schedule() 相继返回了 -1 !丢弃此报文!
static int tcp_try_rmem_schedule(struct sock *sk, struct sk_buff *skb,
unsigned int size)
{
if (atomic_read(&sk->sk_rmem_alloc) > sk->sk_rcvbuf ||
!sk_rmem_schedule(sk, skb, size)) {
if (tcp_prune_queue(sk) < 0)
return -1;
if (!sk_rmem_schedule(sk, skb, size)) {
if (!tcp_prune_ofo_queue(sk))
return -1;
if (!sk_rmem_schedule(sk, skb, size))
return -1;
}
}
return 0;
}
也就是说,此刻 Server 端的sk已经不去接收新的报文了!但它之前通告的窗口明明还有 874 字节, 所以 Clinet 才会不停地重传….
解决方案
那么这个时候sk是真的装不下新的报文了吗?显然不是,它自己的线性空间已经腾出 202 字节了,况且还有 3840 字节的非线性空间可以使用。
所以我们可以将tcp_try_rmem_schedule修改为即使tcp_prune_queue失败(没有能把sk->sk_rmem_alloc压缩到sk->sk_rcvbuf之内),如果此时接收队列尾的sk_buff可以容纳这个报文的话,还是让其返回成功。
static int tcp_try_rmem_schedule(struct sock *sk, struct sk_buff *skb,
unsigned int size)
{
if (atomic_read(&sk->sk_rmem_alloc) > sk->sk_rcvbuf ||
!sk_rmem_schedule(sk, skb, size)) {
- if (tcp_prune_queue(sk) < 0)
+ if (tcp_prune_queue(sk) < 0 &&
+ size > skb_tailroom(skb_peek_tail(sk)) &&
+ size > sk->sk_forward_alloc)
+
return -1;
if (!sk_rmem_schedule(sk, skb, size)) {
if (!tcp_prune_ofo_queue(sk))
return -1;
if (!sk_rmem_schedule(sk, skb, size))
return -1;
}
}
return 0;
}